
1. 배경
쿠버네티스 클러스터를 구성하면서 모니터링 시스템으로 주로 프로메테우스를 구축해서 사용하였습니다. 쿠버네티스 위에서 운영하는 서비스의 경우 안정적인 운영을 위해 HA를 구조로 운영하고 있습니다. 프로메테우스는 메트릭을 발생시키는 익스포터에서부터 Pull 해서 데이터를 가져오고, 수집한 메트릭을 TSDB 구조의 Local Disk에 저장하기 때문에(External DB도 사용은 가능) 프로메테우스가 다운되면 복구되는 시간 동안 메트릭이 누락되게 됩니다. 하지만 프로메테우스에서 이러한 HA 구성을 지원하지 않고 이를 타노스를 통해 구성할 수 있습니다. 또한 멀티 프로메테우스 서버를 통합하여 쿼리 할 수 있는 기능을 제공해서 여러 개의 쿠버네티스 클러스터를 운영하고 있는 상황에서 적합한 서비스라고 생각해 도입하기 위해 테스트한 내용을 기록합니다.
Thanos의 목적 (thanos github 출처)
- Global query view of metrics.
- Unlimited retention of metrics.
- High availability of components, including Prometheus.
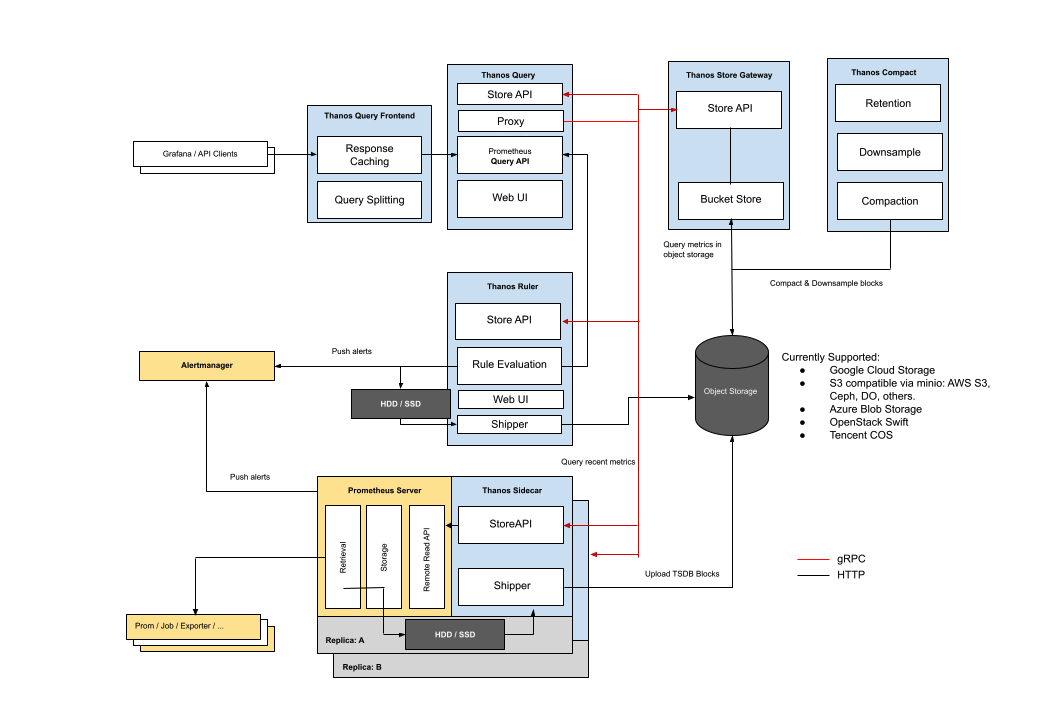
타노스의 전체 아키텍처를 보면 다음과 같습니다. 타노스의 구조는 크게 2가지가 존재합니다. Receiver를 따로 구축 하는 구조와, Prometheus에 Sidecar로 Thanos를 붙여 구축할 수 있습니다. 위의 그림은 Sidecar 구조의 아키텍처입니다. 위의 그림과 같이 전체 적인 흐름을 보면 다소 복잡해 보일 수 있지만 간단하게 정리하면 다음과 같습니다.
- Exporter를 통해 발생한 Metric을 Prometheus Server에서 수집
- Promhetues Server에서 수집한 메트릭을 Thanos SideCar를 통해 Object Storage로 전송 및 저장
- Thanos Query에서 최근 데이터는 Thnos SideCar를 통해 쿼리, 오래된 데이터는 Object Storage에서 조회
- Grafana에서 Thanos Query로 데이터 조회 및 시각화
Prometheus로 HA 구성을 못하는 이유
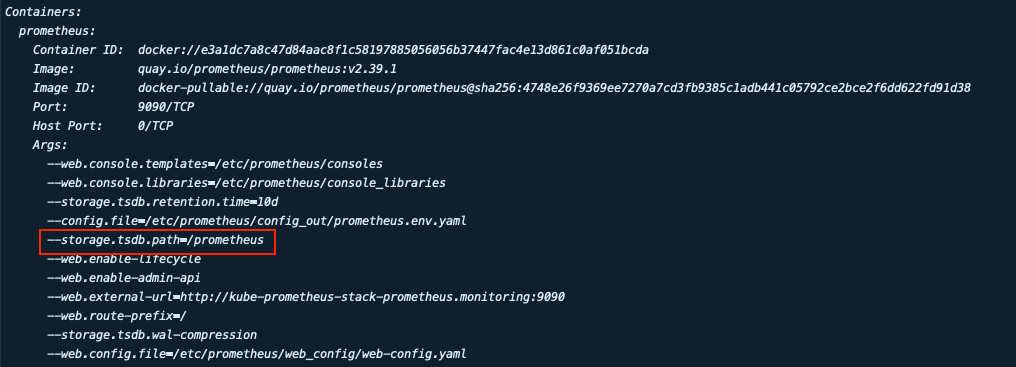
Prometheus HA 구성하기 위해서 복제된 파드간 데이터를 공유할 수 있어야됩니다. 프로메테우스는 tsdb(TimeSeriesDB) 데이터를 사용하는데.(아래 그림의 데이터 저장 경로 참조) 이를 PVC로 마운트하고 replicas를 늘려 여러 파드에서 한 개의 볼륨을 마운트 하면 HA 구성을 할 수 있다고 생각할 수 있지만 Prometheus는 Statefulset으로 생성되기 때문에 복제된 파드들이 한 개의 PVC를 마운트 할 수 없습니다.(Statefulset의 경우 VoluemeTeplate을 통해 볼륨을 동적으로 생성하여 파트당 각각의 볼륨을 마운트 한다)
꼼수를 부려 replicas들이 한 PVC를 마운트 하여(Local Storage PVC로 NFS가 구축된 경로를 마운트 하는 등) 같은 데이터셋을 볼 수 있게 하여도, 각 replicas들이 동일한 데이터를 보내 중복데이터가 생겨 쿼리를 하는데 시간이 오래 걸리게 됩니다. 또한 이러한 HA구조에서 복제된 파드들 간에 통신하는 과정이 필요하기 때문에 이러한 기능을 제공돼야 됩니다. (Elasticsearch 또한 Statefulset으로 HA 구성을 하면 Master와 Node로 구분되어 각 역할을 수행합니다.)
Thanos Deduplication & Compact
Thanos는 위의 문제를 다음과 같은 방식으로 해결합니다. Prometheus에서 제공하는 external_labels 을 통해 각 인스턴스에 레이블을 설정하고 thanos queryer에서 --query.replica-label 을 설정해 중복제거의 기준이 되는 레이블을 설정하여 Deduplicate 작업을 수행해 쿼리 속도를 향상합니다.
타노스는 타노스 클러스터에 포함되지 않는 싱글톤으로 동작하는 Compactor라는 컴포넌트를 제공하는데 Compactor에서 여러 개의 작은 사이즈의 블록을 하나로 통합하는 Vertical Compact 기능을 제공해 Bucket의 전체 사이즈를 줄이고, 오래된 데이터의 경우 청크의 샘플링 수를 줄이는 다운 샘플링을 통해 대용량 쿼리의 속도를 높입니다.
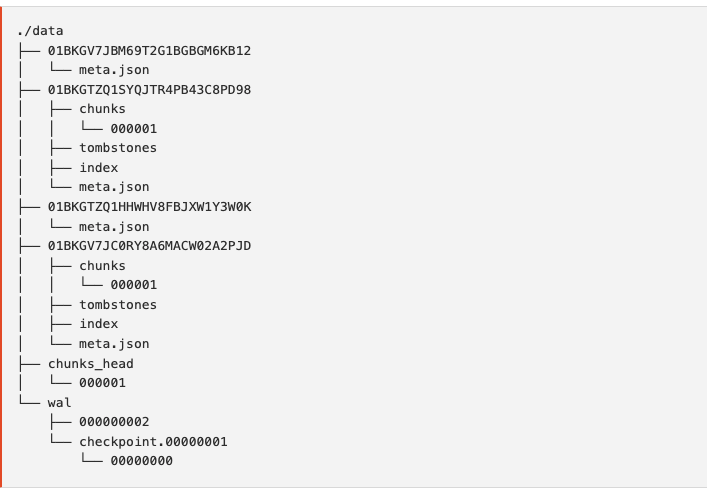
Prometheus의 데이터 구조는 다음과 같습니다. 수집된 sameples는 2시간 단위의 Block으로 그룹화됩니다. 생성된 Block 내부에는 chunk 디렉터리를 포함한 index, meta.json 파일이 생성되는데, samples는 chunk 디렉토리 내에 한 개 이상의 segments로 저장됩니다. API를 통해 삭제하게 되면 tomston 파일에 해당 레코드를 기록합니다. 현재 들어오는 samples 데이터는 프로메테우스가 재시작할 때 발생할 수 있는 WAL과 출동을 방지하기 위해 메모리에 유지됩니다.
WAL(Wrte-Ahead-log : database에서 Write, modify, delete를 하기 전에 events를 먼저 로그로 저장합니다. In memory DB의 경우 데이터베이스가 다운되면 메모리에 저장된 데이터를 모두 유실할 수 있기 때문에 이에 대한 방지가 가능하고 관계형 데이터베이스에서 ACID 중 Durability를 유지하기 위해 사용합니다. Prometheus에서 WAL은 event를 기록하고 프로메테우스가 시작될 때 memory 상태를 복원하는 용도로만 사용합니다.
2. Prometheus-Thanos 설치
2-1. Minio 설치
Object Storage를 사용하기 위해 Minio를 설치합니다. 아래 Minio 파드 매니페스트를 다운로드하여 파드를 생성하는데, Minio는 data를 저장하는 볼륨으로 hostPath를 권장하기 때문에 이를 유지하기 위해 NodeSelector로 노드를 지정합니다. 해당 부분을 맞게 변경 후 파드를 생성합니다.
curl https://raw.githubusercontent.com/minio/docs/master/source/extra/examples/minio-dev.yaml -O이후 9090 포트를 연결해 접속하여 minioadmin/minioadmin을 통해 접속하면 다음과 같이 Minio가 정상적으로 배포된 것을 확인할 수 있습니다.
이후 타노스용 버킷과 유저를 생성한 후 Prometheus에서 접근하기 위한 secret을 생성합니다. endpoint의 경우 ClusterIP를 생성해 Service 명으로 접속할 수 있도록 합니다.
#minio_conf.yml
type: s3
config:
bucket: thanos
endpoint: minio-internal:9090
access_key: thanos
access_key: password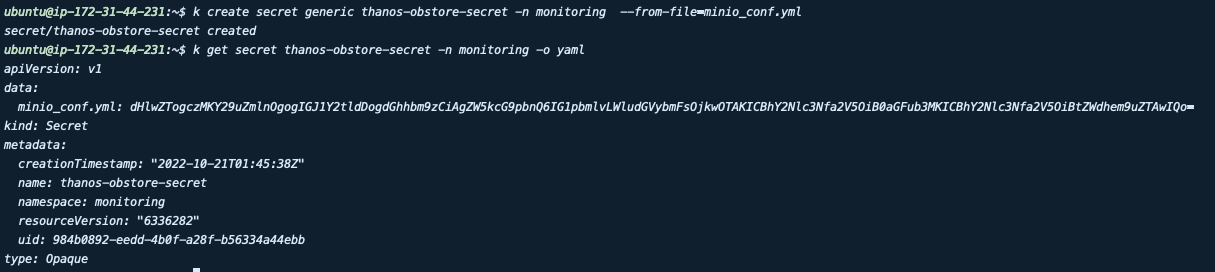
2-2. Kube-Prometheus 설정
우선 Kube-prometheus를 설치합니다. Helm을 통해 배포하는데 프로메테우스의 Helm repo의 경우 Prometheus-operator는 더 이상 지원하지 않고 Kube-prometheus-stack으로 통합되었습니다. 두 가지 repo 모두 타노스 관련 values.yaml을 지원하며, Kube-prometheus-stack으로 설치를 진행합니다.
Promehtues-operator의 values.yml
thanos 부분에 objectStorageConfig 항목을 추가해 배포합니다.
thanos:
image: "quay.io/thanos/thanos:v0.27.0"
objectStorageConfig:
key: minio_conf.yml
name: thanos-obstore-secret
version: v0.27.0
prometheus:
thanosService:
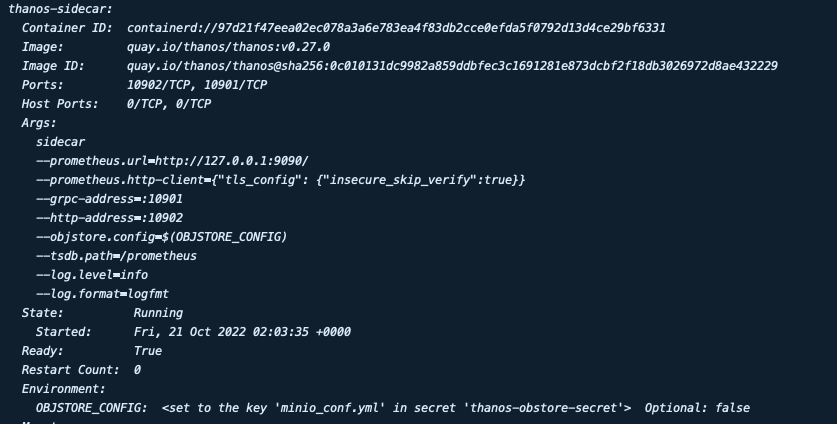
enabled: true 이후 프로메테우스 파드를 확인하면 컨테이너의 수가 기존 2개에서 3개로 늘어나고 thnos-sidecar가 추가된 것을 확인할 수 있습니다.
2-3. Thanos-Query 설치
프로메테우스 Sidecar를 설정한 후 타노스를 설치하기 위해 values를 생성합니다. helm chart는 bitnami/thanos를 사용합니다. stores에서 위의 thnos side카의 주소를 입력합니다. 해당 주소는 kube-prometheus-stack에서 Thanos 설정을 한 후 설치하면 서비스가 생성되기 때문에 sidecar 서비스 명을 입력해 연결합니다.
#thanos.yaml
objstoreConfig: |-
type: s3
config:
bucket: thanos
endpoint: thanos-internal:9090
access_key: thanos
secret_key: password
insecure: true
querier:
stores:
- kube-prometheus-kube-prome-thanos-discovery:10901
service:
type: ClusterIP
ports:
http: 9090
nodePorts:
http: "31254"
cplusterIP: ""
bucketweb:
enabled: true
compactor:
enabled: false
storegateway:
enabled: false
ruler:
enabled: true
persistence:
enabled: true
storageClass: "nfs-client"
accessModes:
- ReadWriteOnce
size: 10Gi
config: |-
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum(http_inprogress_requests) by (job)
alertmanagers:
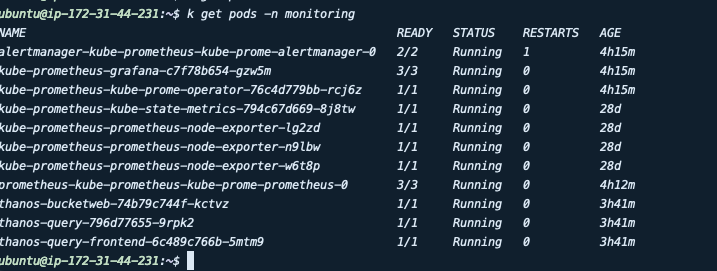
- http://kube-prometheus-kube-prome-alertmanager:9093이후 pod를 확인하면 타노스가 생성된 것을 확인할 수 있습니다.
thanos-query Deployment를 NodePort로 연결해 웹으로 접속 시 Prometheus와 비슷한 화면의 타노스를 확인할 수 있습니다.
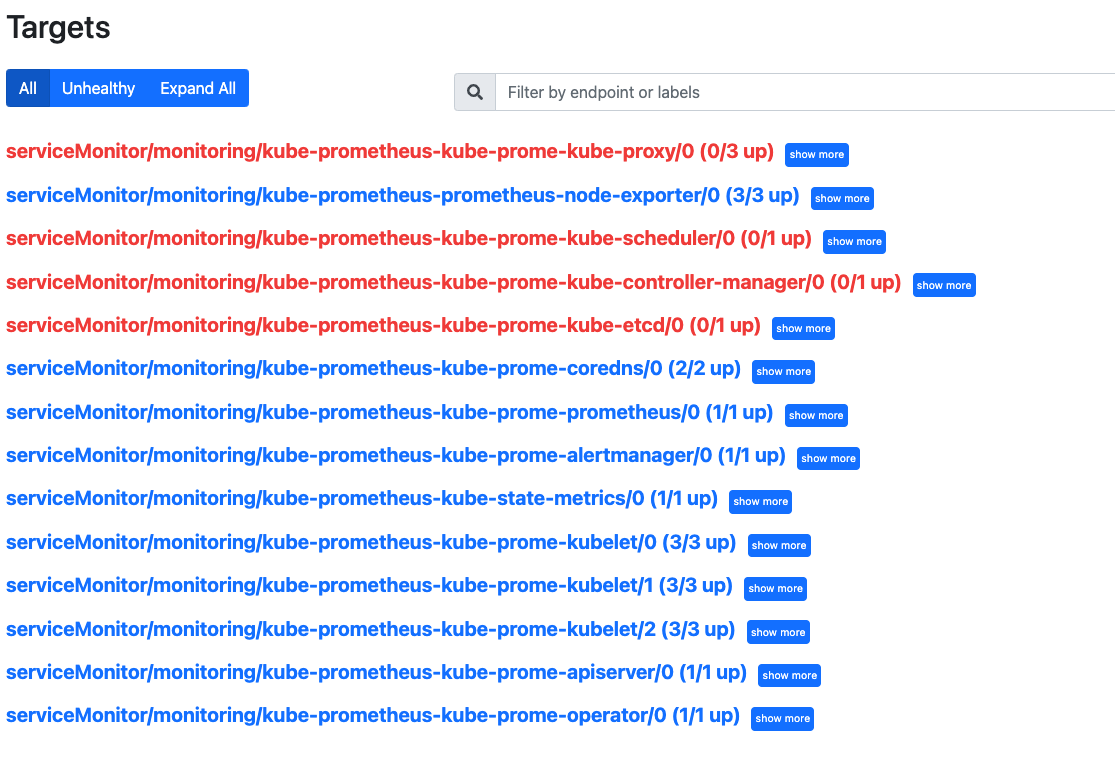
Status/Targets를 통해 수집하는 Exporter 목록을 확인할 수 있습니다. Node-exporter와 Kube-state-metrics는 Kube-state-metrics를 통해 자동으로 설치됩니다. 그 외에 Control-plane에서 가져오는 Metric(control-Plane, Etcd 등)은 Down으로 되어있는데 이는 Secured로 되어있어서 메트릭을 수집할 수 있도록 설정해야 합니다
# ETCD 설정
# /etc/kubernetes/manifests/etcd.yaml 변경
- --listen-metrics-urls=http://0.0.0.0:2381
# kube-proxy 설정
# k edit cm kube-proxy -n kube-system 변경
metricsBindAddress: "0.0.0.0:10249"
#kube-controller,kube-scheduler 설정
# /etc/kubernetes/manifest/ kube-scheduler.yaml 변경
- -- bind-address= 0.0.0.02-4. Grafana 설정
이후 그라파나에서 타노스에서 수집한 메트릭을 시각화하기 위해 Datasource를 추가합니다. thanos-query로 서비스가 생성되기 때문에 ClusterIP의 주소를 다음과 같이 입력 후 생성하면 정상적으로 데이터를 수집하는 것을 확인할 수 있습니다.
!
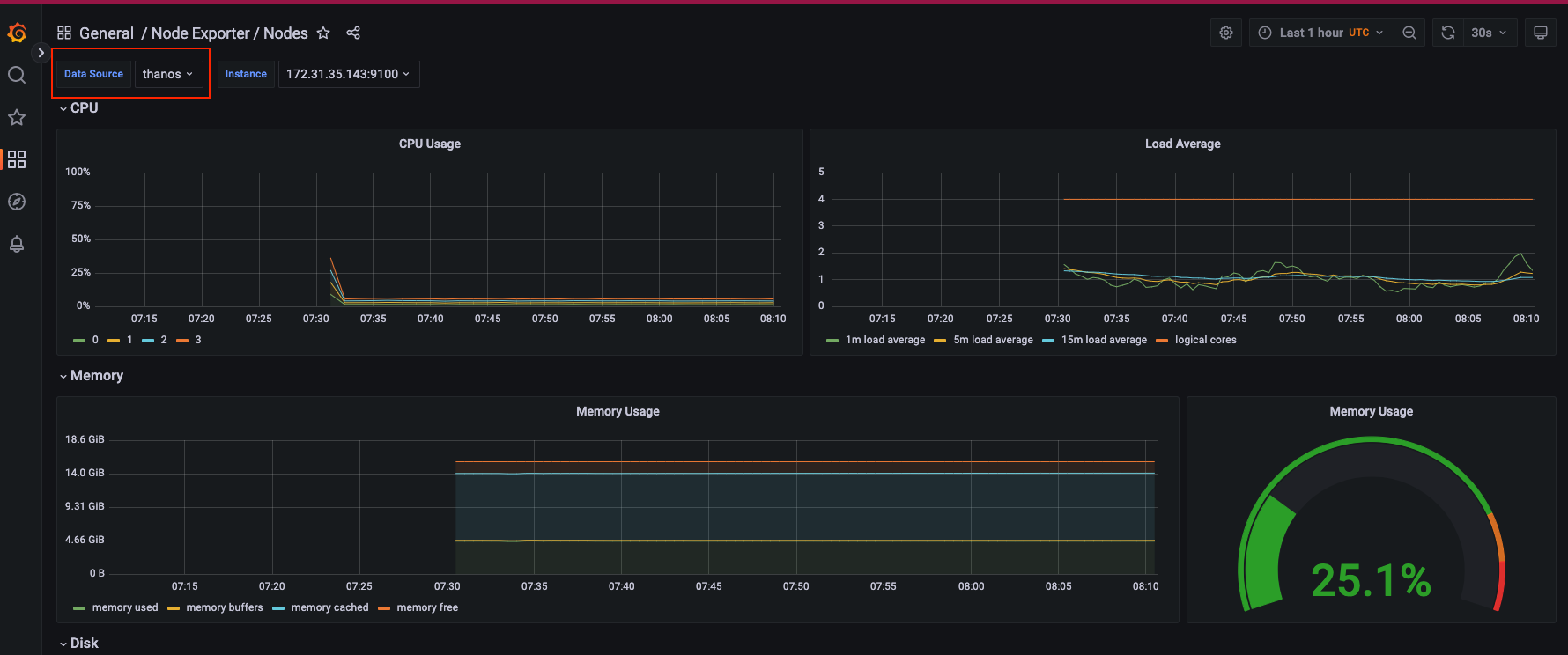
이후 기본으로 추가되는 대시보드에서 Data Source를 Thanos로 변경해도 정상적으로 시각화되는 것을 확인할 수 있습니다.
3. Multi-cluster 추가
멀티클러스터 환경을 위해 K8S를 새로 구성하고 프로메테우스를 위의 2번과 동일하게 helm을 이용해 설치합니다. 타노스에서 동일한 minio bucket을 바라보게 하기 위해 minio_conf.yml 파일에서 endpoint를 외부 클러스터에서 접근할 수 있도록 nodeport 주소로 설정하고, 이전에 설치한 grafana를 통해 접근하기 위해 추가 설치할 필요가 없어 grafana.enable 값만 변경해 주었습니다.
이후 Thanos Query에서 새로 생성한 Prometheus에 접근할 수 있도록 stores에 주소를 추가합니다. 현재 테스트를 위해 노드 포트를 이용해 연결하였습니다.
#thanos.yml
querier:
stores:
- kube-prometheus-kube-prome-thanos-discovery:10901
- 새로 추가한 prometheus-sidecar의 주소 입력이후 thanos-clutser를 update 합니다. thnos-query에서 Stores에 접속하면 다음과 같이 sidecar가 추가된 것을 확인할 수 있습니다.
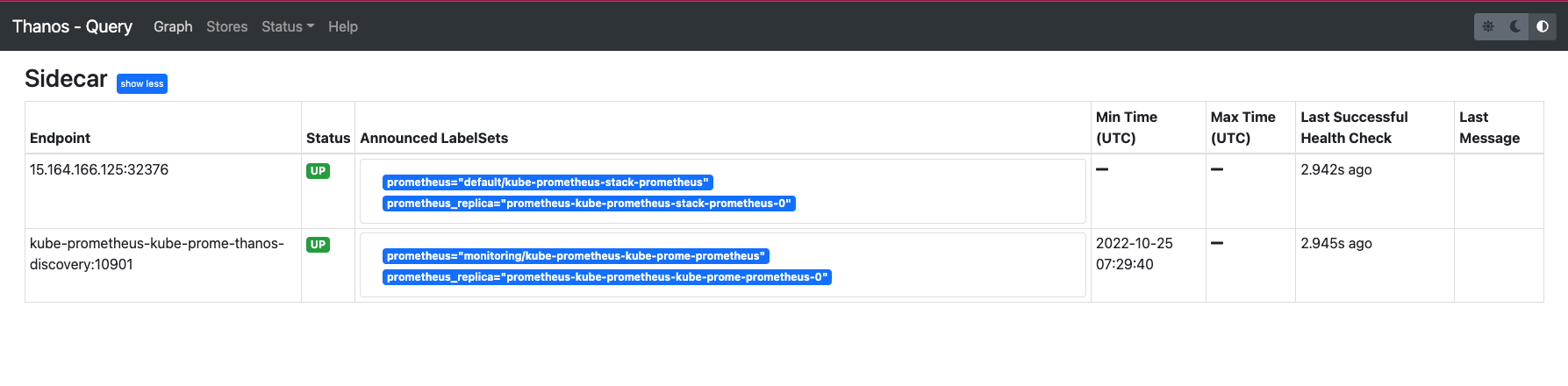
다음과 같이 클러스터를 추가하여 2개의 쿠버네티스 클러스터를 Grafana에서 모니터링할 수 있습니다. 하지만 클러스터가 늘어날 경우 이를 구분할 수 있도록 Label을 추가해야 합니다. 이는 Prometheus 설치 시 사용한 values.yaml 에서 이를 설정할 수 있습니다.
#values.yaml
externalLabels:
cluster: "cluster-prd"클러스터 구분을 위해 cluster-prd cluster-dev로 레이블을 설정해 프로메테우스를 배포하였습니다. 이후 메트릭을 조회하면 다음과 같이 Metrics에 clutser label값이 추가되어 설정된 것을 확인할 수 있습니다.

이를 이용해 그라파나에서 대시보드를 구성할 때 variable로 cluster를 추가하여 각 클러스터를 구분해서 모니터링할 수 있습니다.
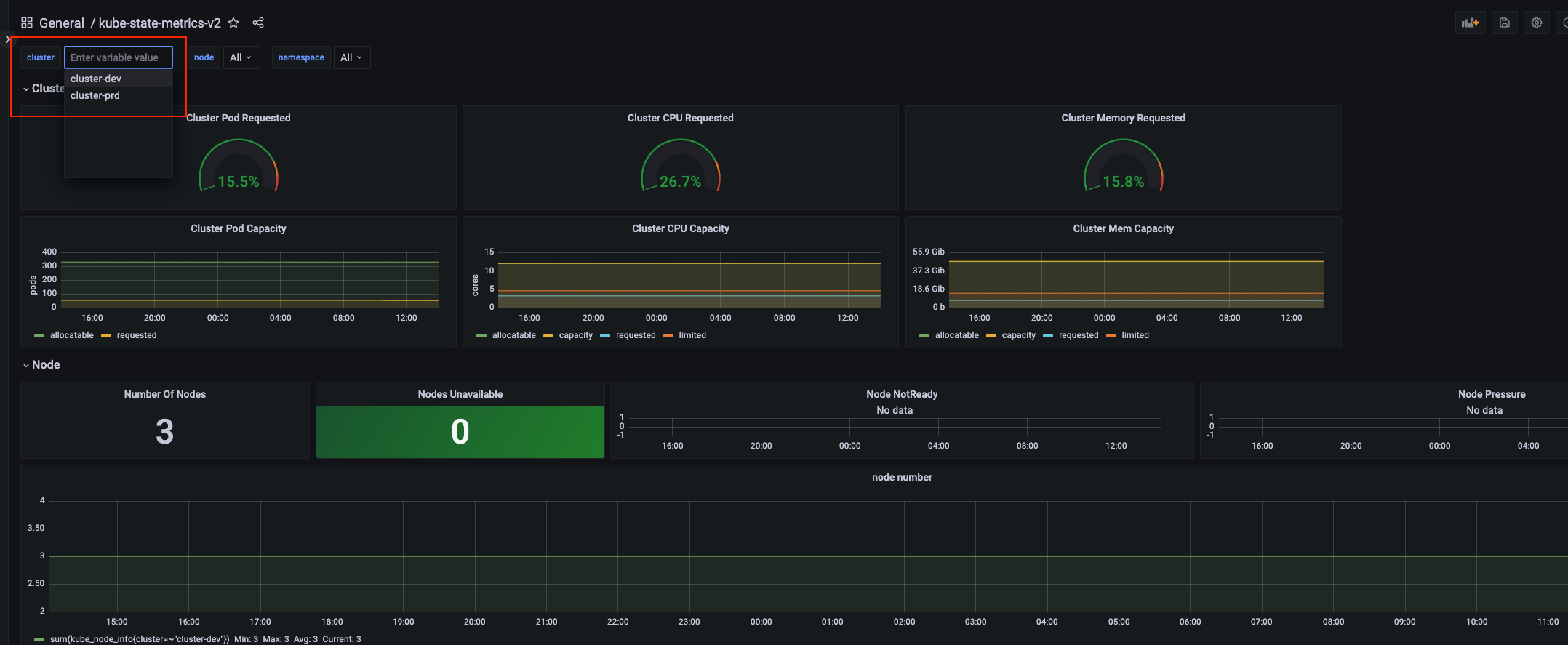
4. 프로메테우스 HA 구성
위의 과정을 통해 멀티클러스터 환경에서 모니터링 구조를 구성하였지만 타노스의 주요 목적인 프로메테우스의 HA 구성을 적용하지 못하였습니다. 이를 위해 Prometheus values.yaml 파일을 수정합니다.
prometheus
replicas: 3duplication을 위해 external_labels를 설정해야 되는데 replicas를 늘리면 자동으로 prometheus_replica 라는 label을 생성되어 따로 설정할 필요 없습니다. 이후 추가로 생성된 파드를 thanos와 연결하기 위한 서비스를 각 각 생성합니다.(아래의 서비스는 디버깅을 위해 생성하고 실제로는 headless 서비스 한 개에 전부 연결합니다)
apiVersion: v1
kind: Service
metadata:
name: prometheus-0-service
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9090"
namespace: monitoring
labels:
name: prometheus
spec:
selector:
statefulset.kubernetes.io/pod-name: prometheus-kube-prometheus-kube-prome-prometheus-0
ports:
- name: prometheus
port: 8080
targetPort: 9090이후 생성된 파드를 타노스에 연결하기 위해 querier에 서비스 주소를 입력하고, duplicate를 위해 replicaLabel을 rometheus_replica로 수정한 후 타노스를 업그레이드를 합니다.
#thanos values.yaml
querier:
replicaLabel: prometheus_replica
stores:
- kube-prometheus-kube-prome-thanos-discovery:10901
- prometheus-0-service-ha:10901
- prometheus-1-service-ha:10901
- prometheus-2-service-ha:10901이후 타노스 대시보드에 접속해 Stores를 통해 타깃을 확인하면 Sidecar가 늘어난 것을 확인할 수 있습니다.

Duplication을 테스트하기 위해 테스트로 메트릭 조회 시 다음과 같이 정상적으로 중복제거가 되는 것을 확인할 수 있습니다. Use Deduplication을 체크할 경우 다음과 같이 두개의 메트릭이 발생하지만 체크하지 않을 경우 각 프로메테우스마다 한개 씩 메트릭을 수집하는 것을 확인 할 수 있습니다.

)

실제로 운영 시 파드마다 서비스를 전부 생성할 필요 없이 기존에 생성된 thanos-discovery 서비스에 엔드포인트로 각 파드가 연결된 것을 확인 할 수 있습니다. 해당 서비스를 연결할 경우 thanos 대시보드에는 한 개로 보이지만 연결된 프로메테우스 파드가 다운될 경우 자동으로 다른 프로메테우스에 연결되어 사용할 수 있습니다.

위와 같이 현재 prometheus 2번 파드에 연결되어 메트릭을 수집한 상황에서 강제로 2번을 다운시킬 경우 아래와 같이 Runngin 상태의 파드를 연결해서 메트릭을 동일하게 수집합니다.

'Kubernetes' 카테고리의 다른 글
| EFK Stack을 이용한 쿠버네티스 로깅 스택 구축#2 (0) | 2023.10.12 |
|---|---|
| EFK Stack을 이용한 쿠버네티스 로깅 스택 구축#1 (0) | 2023.10.12 |
| ArgoCD,Jenkins를 이용한 쿠버네티스 배포 (0) | 2023.10.12 |
| Kubernetes HA 구성을 위한 Pod Scheduling (0) | 2023.10.12 |
| 쿠버네티스 멀티클러스터 관리하기(Feat. Teleport) (1) | 2023.10.12 |