
1. Overview
쿠버네티스에서 Deployment를 생성하면서 안정적인 서비스 유지를 위해 여러 개의 파드로 구성할 때가 있습니다. 이는 보통 Replicas를 2개 이상으로 설정해 파드를 여러 개 생성하여 하나의 파드가 문제가 생겨도 정상적으로 서비스가 동작할 수 있도록 합니다. 하지만 Deployment Spec에서 Replicas 개수만 늘릴 경우 하나의 노드에서 여러 개의 파드가 생성되는 경우가 있습니다. 그럴 경우 생성된 노드가 다운이 될 경우 서비스에 문제가 생깁니다(다른 노드에 바로 배포가 되지만 배포가 되기까지의 시간이 걸리기 때문에 무중단이 불가). 그렇기 때문에 일반적으로 여러 노드에 파드를 분산하여 배포하도록 설정합니다. 이를 위해 파드 스케줄링 방법과 이를 외부에서 접근하기 위해 서비스를 연결하는 방법을 알아봅니다.
쿠버네티스에서 파드를 노드에 할당 과정은 Kube-scheuler가 담당합니다. 대략적으로 파드의 리소스 요청과 노드의 할당가능한 자원을 고려해 어떤 노드에 파드를 배포할 것인지 스케줄링 합니다. 자세한 동작 과정은 해당 문서를 참조. 하지만 Kube-scheduler가 아닌 사용자가 배포 위치를 지정하기 위해서는 4가지 방법이 존재합니다.
- nodeSelector
- nodeName
- node affinity
- pod affinity /anti affinity
nodeSector와 nodeName의 경우 사용방법이 매우 간단하기 때문에 따로 다루진 않겠습니다.
2. Pod Scheduling
2-1. Node affinity
node affinity는 파드가 특정 노드에 생성되지 않도록 제한을 둘 수 있도록 하면서 nodeSelector와 비슷하지만 좀 더 세부적인 규칙을 지정할 수 있습니다. affinity의 경우 조건이 만족하지 않으면 생성되지 않는 hard와 만족하지 않아도 생성되는 soft로 구분 합니다.
requiredDuringSchedulingIgnoredDuringExecution: 조건을 충족시키지 않으면 생성되지 않음preferredDuringSchedulingIgnoredDuringExecution: 조건을 충족시키지 않아도 생성은 되지만 조건이 만족하는 노드를 선호함.
예를 들어 다음과 같이 node에 region 과 hw,network 의 레이블을 지정하였습니다.

이후 nginx deployment를 다음과 같이 Affinity를 적용합니다. region은 ap-northeast1, ap-northeast2 가 지정 되어있는 노드에만 생성하고 hw 또는 network가 지정되어 있으면 해당 노드에 선호하도록 설정하였습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-node-affinity-test
spec:
selector:
matchLabels:
app: nginx-node-affinity-test
template:
metadata:
labels:
app: nginx-node-affinity-test
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: aws.ec2.region
operator: In
values:
- ap-northeast1
- ap-northeast2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: ec2.hw
operator: In
values:
- ssd
- weight: 10
preference:
matchExpressions:
- key: network
operator: In
values:
- infi
containers:
- name: nginx-node-affinity-test
image: nginx
ports:
- containerPort: 80이후 파드가 생성된 노드를 확인하면 region 조건에 만족하는 node는 worker1과 worker2입니다. 이후 preferredDuringSchedulingIgnoredDuringExecution를 통해 선호도를 계산하는데 hw 항목의 ssd가 설정된 worker1는 1점(weight 값) network 항목의 infi가 설정된 worker2는 2점을 받아 더 높은 선호도를 받아 worker2에 할당되게 됩니다.

2-2. Pod Affinity/Anti Affinity
Pod affinity는 Node affinity와 비슷하게 사용됩니다. 다만 다른 점은 규칙의 기준이 노드가 아닌 파드입니다. 예를 들어 특정 파드가 있는 곳과 동일한 노드에 배치(Affinity)하거나 배치하지 않게 합니다(Anti affinity). 이러한 기준의 사용하기 위해서 Pod의 Label을 이용합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 1
template:
metadata:
labels:
app: store
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-node-affinity-test
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine다음과 같이 위에서 생성한 nginx와 동일한 노드에 redis 파드를 생성하기 위해 PodAffinity를 설정합니다(반대의 경우 podAntiAffinity를 설정)
하지만 podAntifAffinity와 다르게 nodeAnitiAffinty는 존재하지 않습니다. 해당 기능은 Taint/Toleration을 통해 사용합니다.
2-3. Taint/Toleration
Taint는 노드에 다음과 같이 생성합니다 kubectl taint node worker1 key:value:effect taint가 설정되어 있는 노드는 일반적으로 Pod가 생성되지 않는데, 이를 생성하기 위해서는 Toleration을 파드에 설정해야 합니다. effect의 경우 다음과 같이 3개가 존재합니다.
- NoSchedule : Toleration이 설정되어야만 노드에 생성될 수 있다.
- PreferNoSchedule : Noschedule의 soft 버전으로 일반적으로 생성되지 않지만 필수는 아니다(다른 노드에 자원이 없는 경우 생성될 수 있음)
- NoExecute : Toleration이 설정되어있지 않으면 바로 삭제된다( NoSchedule의 경우 Pending 상태로 남아있음)
파드에 다음과 같이 Tolerations를 작성해 worker3 노드에 할당할 수 있도록 설정합니다. Toleration을 설정한다고 해당 노드에 생성되는 것이 아니라 생성될 수 있는 권한을 주는 것이기 때문에 nodeName을 통해 일시적으로 지정합니다.
 Operator의 경우 Equal과 Exists가 있는데 Exists의 경우 key만 일치하면 허용하기 때문에 value를 지정하지 않습니다. 같은 파드에 스케줄 정책을 두 개씩 설정하고 비교하였을 때 우선순위를 같은 정책은 다음과 같습니다.
Operator의 경우 Equal과 Exists가 있는데 Exists의 경우 key만 일치하면 허용하기 때문에 value를 지정하지 않습니다. 같은 파드에 스케줄 정책을 두 개씩 설정하고 비교하였을 때 우선순위를 같은 정책은 다음과 같습니다.
apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pytorch name: pytorch2 spec: containers: - image: pytorch/pytorch name: pytorch2 resources: {} tolerations: - key: "isgpu" operator: "Equal" value: "true" effect: "NoSchedule" nodeName: worker3 restartPolicy: Always status: {}- nodeSelector vs nodename : nodeSelector
- Taint vs NodeSelector : Taint
- affinity: nodeselector : nodeSelector
3. Deployment HA 구성
Kubernetes의 Deployment를 통해 HA 구성할 때 위의 방법을 사용할 수 있습니다. 가장 간단한 방법은 Deployment를 생성하기 전 서비스를 먼저 생성한 후 Deployment를 생성하면 Kube-scheduler가 자동으로 균등하게 배포합니다. 하지만 특정한 이유로 이를 지정해서 생성해야 할 때 topologySpreadConstraints 와 PodAntiAffinity 를 통해 설정할 수 있습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80PodAntiAffinity의 경우 topologykey를 통해 node의 조건(NodeAffinity에서 Label의 역할)이 되는 기준을 설정할 수 있습니다. 이를 이용해 kubernetes.io/hostname 이 지정된 노드에 app=nginx label의 레이블을 가진 파드가 있을 경우 해당 노드를 피하는 조건으로 각 각 다른 노드에 생성되도록 지정합니다.
단순히 각 노드를 다르게 배포하기 위해서는 위의 방법으로 충분하지만 좀 더 세부적인 조건을 이용하기 위해서는 topologySpreadConstraints를 사용합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80PodAntiAffinity동일한 방법으로 labelSelector를 통해 파드를 지정한 후 topologykey를 통해 노드를 지정합니다. maxSkew는 균등하게 분배되지 않는 정도 나타냅니다. 일반적으로 topologySpreadConstraints 의 경우 대형 클러스터에서 여러 개의 제약조건을 통해 HA 구성을 통해 배포할 때 사용합니다. 각 각의 정책은 AND 조건으로 계산됩니다. 예를 들어 zone으로 구성된 노드 그룹에 비율을 나누고 각 노드에는 하나씩 배포하는 방법. 자세한 문서 참조
4. Deployment HA Service 연결
위의 방법으로 구성한 Deployment를 HA 구성하였는데 이를 사용하기 위한 목적으로는 크게 두 가지가 있다. 첫 번째는 부하분산을 통해 파드에 너무 많은 requests가 가지 않도록 하기 위해, 한 노드가 down 되어도 서비스 중단 없이 사용할 수 있도록 하기 위해 사용한다. 생성한 Deployment를 접근하기 위해서 서비스를 생성해야하는데 다음과 같은 방법을 사용할 수 있다. 이를 테스트하기 위해 생성된 파드에서 nginx의 index페이지에 노드 명을 작성해 접근시 생성된 노드의 이름을 확인할 수 있도록 변경하였다.
4-1. ClusterIP
ClusterIP의 경우 쿠버네티스에서 기본적으로 사용할 수 있는 Service의 종류로 가장 큰 특징은 클러스터 내부에서만 사용 할 수 있습니다. 그렇기 때문에 파드와 파드간 통신에서만 사용할 경우 쉽게 생성할 수 있습니다.(e.g backend 파드와 연결되는 db의 경우 외부접속이 필요 없이 클러스터 내부의 통신만 이용한다)
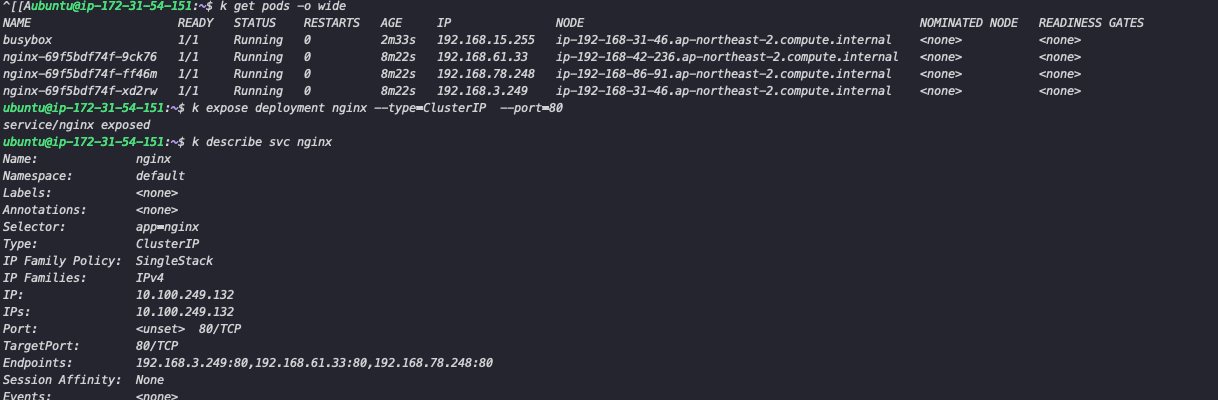
위와 같이 expose 명령어로 서비스를 생성한 후 endpoint를 조회하면 생성된 파드 3개가 연결된 것을 확인할 수 있습니다. 이후 테스트를 위한 파드를 생성 후 내부에서 Service IP로 접근하였을 때 3개의 파드에 분산하면서 접근합니다.
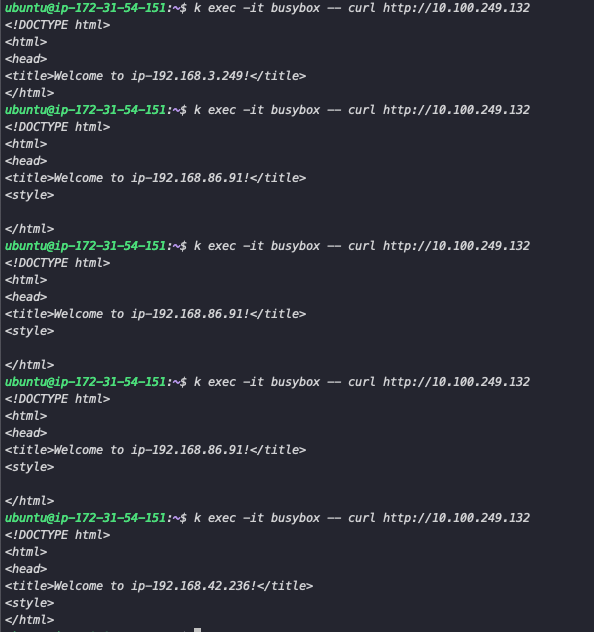
4-2. LoadBalancer
하지만 ClusterIP는 클러스터 내부에서만 접근이 가능하고 외부에서 접근하기 위해서는 Loadbalancer 또는 Ingress를 사용해야 합니다. LoadBalancer는 Cloud Provider에서 생성한 클러스터는 기본으로 제공하지만 오픈소스로 클러스터를 구성했을 경우 MetalLB로 생성해 사용할 수 있습니다. 현재 클러스터에는 Metal Lb가 설치되어 있지 않아 LB가 제공되는 EKS에서 테스트할 때 동일하게 분산되며 접근하는 것을 확인할 수 있습니다.
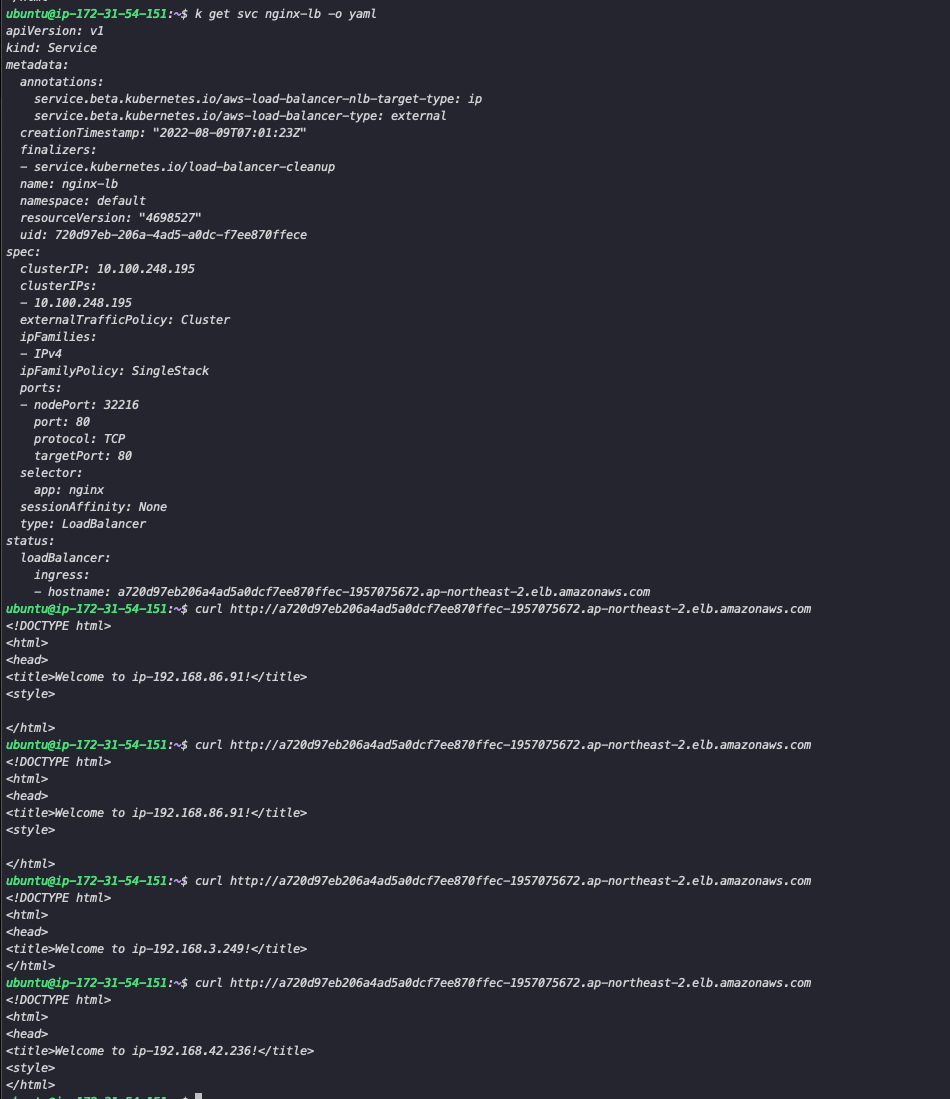
4-3. Ingress
ingress는 쿠버네티스 외부에서 유입되는 네트워크를 관리하는 resource로, 외부 접근 가능 URL를 제공, TLS, Domain 기반 접근 등의 기능을 제공합니다. 주로 nginx-ingress를 많이 사용하는데 ingress를 설치하기 위한 서비스 로드 밸런서가 필요하지만 bare-metal에서는 ingress-controller를 NodePort로 배포하여 사용할 수 있습니다. (ingress-controller의 타입을 NodePort로 설치한다)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.3.0/deploy/static/provider/baremetal/deploy.yaml위의 커맨드로 Ingress-controller를 설치한 후 ingress-nginx 네임스페이스에 파드가 실행되는 것을 확인하면 파드에 접근하기 위한 Ingress를 생성합니다. service에서 Deployment가 연결된 ClusterIP의 이름을 지정해 줍니다. host를 지정해 도메인을 통해 접속할 수 있지만 설정하지 않으면 IP를 통해 접속할 수 있습니다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ing
spec:
rules:
#- host: nginx.example.com
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx
port:
number: 80
ingressClassName: nginx이후 ingress-controller의 주소로 노드포트를 통해 접근하면 Loadbalancer와 마찬가지로 파드가 분기되어 접속하는 것을 확인할 수 있습니다.
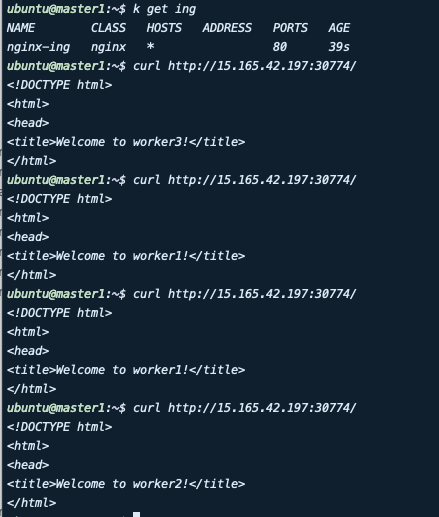
4-4. NodePort
일반적으로 테스트용으로 많이 쓰는 노드포트의 경우 이러한 상황에서 적합하지는 않지만 구현은 가능합니다. 동일하게 nginx deployment를 노출하는 type으로 nodePort를 선택하고 생성 후 주소로 접근하면 아래와 같이 세 개의 파드에 분기되며 접근하는 것을 확인할 수 있습니다. 다만 배포한 파드의 워커 수만큼 접근할 수 있는 주소가 생깁니다.
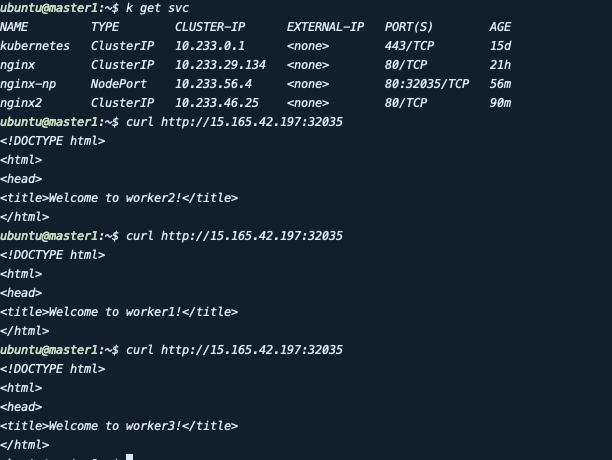
위와 같이 파드 3개가 각 각 다른 노드에 배포된 상황에서 한 노드가 다운되어도 내부에서 NAT가 반영되어 나머지 두 노드를 통해 접근합니다. 하지만 실제 서비스에서 다음과 같이 구성할 경우 한 노드가 다운 됐을 경우 IP를 변경해서 접속해야 하기 때문에 적합하지 않습니다.
'Kubernetes' 카테고리의 다른 글
| Thanos를 이용한 Prometheus HA 구성 (1) | 2023.10.12 |
|---|---|
| ArgoCD,Jenkins를 이용한 쿠버네티스 배포 (0) | 2023.10.12 |
| 쿠버네티스 멀티클러스터 관리하기(Feat. Teleport) (1) | 2023.10.12 |
| Kubernetes에서 학습용 Job 생성하기 (0) | 2023.10.12 |
| Kubeflow JupyterNoteBook (0) | 2023.10.12 |
1. Overview
쿠버네티스에서 Deployment를 생성하면서 안정적인 서비스 유지를 위해 여러 개의 파드로 구성할 때가 있습니다. 이는 보통 Replicas를 2개 이상으로 설정해 파드를 여러 개 생성하여 하나의 파드가 문제가 생겨도 정상적으로 서비스가 동작할 수 있도록 합니다. 하지만 Deployment Spec에서 Replicas 개수만 늘릴 경우 하나의 노드에서 여러 개의 파드가 생성되는 경우가 있습니다. 그럴 경우 생성된 노드가 다운이 될 경우 서비스에 문제가 생깁니다(다른 노드에 바로 배포가 되지만 배포가 되기까지의 시간이 걸리기 때문에 무중단이 불가). 그렇기 때문에 일반적으로 여러 노드에 파드를 분산하여 배포하도록 설정합니다. 이를 위해 파드 스케줄링 방법과 이를 외부에서 접근하기 위해 서비스를 연결하는 방법을 알아봅니다.
쿠버네티스에서 파드를 노드에 할당 과정은 Kube-scheuler가 담당합니다. 대략적으로 파드의 리소스 요청과 노드의 할당가능한 자원을 고려해 어떤 노드에 파드를 배포할 것인지 스케줄링 합니다. 자세한 동작 과정은 해당 문서를 참조. 하지만 Kube-scheduler가 아닌 사용자가 배포 위치를 지정하기 위해서는 4가지 방법이 존재합니다.
- nodeSelector
- nodeName
- node affinity
- pod affinity /anti affinity
nodeSector와 nodeName의 경우 사용방법이 매우 간단하기 때문에 따로 다루진 않겠습니다.
2. Pod Scheduling
2-1. Node affinity
node affinity는 파드가 특정 노드에 생성되지 않도록 제한을 둘 수 있도록 하면서 nodeSelector와 비슷하지만 좀 더 세부적인 규칙을 지정할 수 있습니다. affinity의 경우 조건이 만족하지 않으면 생성되지 않는 hard와 만족하지 않아도 생성되는 soft로 구분 합니다.
requiredDuringSchedulingIgnoredDuringExecution: 조건을 충족시키지 않으면 생성되지 않음preferredDuringSchedulingIgnoredDuringExecution: 조건을 충족시키지 않아도 생성은 되지만 조건이 만족하는 노드를 선호함.
예를 들어 다음과 같이 node에 region 과 hw,network 의 레이블을 지정하였습니다.
이후 nginx deployment를 다음과 같이 Affinity를 적용합니다. region은 ap-northeast1, ap-northeast2 가 지정 되어있는 노드에만 생성하고 hw 또는 network가 지정되어 있으면 해당 노드에 선호하도록 설정하였습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-node-affinity-test
spec:
selector:
matchLabels:
app: nginx-node-affinity-test
template:
metadata:
labels:
app: nginx-node-affinity-test
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: aws.ec2.region
operator: In
values:
- ap-northeast1
- ap-northeast2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: ec2.hw
operator: In
values:
- ssd
- weight: 10
preference:
matchExpressions:
- key: network
operator: In
values:
- infi
containers:
- name: nginx-node-affinity-test
image: nginx
ports:
- containerPort: 80이후 파드가 생성된 노드를 확인하면 region 조건에 만족하는 node는 worker1과 worker2입니다. 이후 preferredDuringSchedulingIgnoredDuringExecution를 통해 선호도를 계산하는데 hw 항목의 ssd가 설정된 worker1는 1점(weight 값) network 항목의 infi가 설정된 worker2는 2점을 받아 더 높은 선호도를 받아 worker2에 할당되게 됩니다.
2-2. Pod Affinity/Anti Affinity
Pod affinity는 Node affinity와 비슷하게 사용됩니다. 다만 다른 점은 규칙의 기준이 노드가 아닌 파드입니다. 예를 들어 특정 파드가 있는 곳과 동일한 노드에 배치(Affinity)하거나 배치하지 않게 합니다(Anti affinity). 이러한 기준의 사용하기 위해서 Pod의 Label을 이용합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 1
template:
metadata:
labels:
app: store
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-node-affinity-test
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine다음과 같이 위에서 생성한 nginx와 동일한 노드에 redis 파드를 생성하기 위해 PodAffinity를 설정합니다(반대의 경우 podAntiAffinity를 설정)
하지만 podAntifAffinity와 다르게 nodeAnitiAffinty는 존재하지 않습니다. 해당 기능은 Taint/Toleration을 통해 사용합니다.
2-3. Taint/Toleration
Taint는 노드에 다음과 같이 생성합니다 kubectl taint node worker1 key:value:effect taint가 설정되어 있는 노드는 일반적으로 Pod가 생성되지 않는데, 이를 생성하기 위해서는 Toleration을 파드에 설정해야 합니다. effect의 경우 다음과 같이 3개가 존재합니다.
- NoSchedule : Toleration이 설정되어야만 노드에 생성될 수 있다.
- PreferNoSchedule : Noschedule의 soft 버전으로 일반적으로 생성되지 않지만 필수는 아니다(다른 노드에 자원이 없는 경우 생성될 수 있음)
- NoExecute : Toleration이 설정되어있지 않으면 바로 삭제된다( NoSchedule의 경우 Pending 상태로 남아있음)
파드에 다음과 같이 Tolerations를 작성해 worker3 노드에 할당할 수 있도록 설정합니다. Toleration을 설정한다고 해당 노드에 생성되는 것이 아니라 생성될 수 있는 권한을 주는 것이기 때문에 nodeName을 통해 일시적으로 지정합니다.Operator의 경우 Equal과 Exists가 있는데 Exists의 경우 key만 일치하면 허용하기 때문에 value를 지정하지 않습니다. 같은 파드에 스케줄 정책을 두 개씩 설정하고 비교하였을 때 우선순위를 같은 정책은 다음과 같습니다.
apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pytorch name: pytorch2 spec: containers: - image: pytorch/pytorch name: pytorch2 resources: {} tolerations: - key: "isgpu" operator: "Equal" value: "true" effect: "NoSchedule" nodeName: worker3 restartPolicy: Always status: {}- nodeSelector vs nodename : nodeSelector
- Taint vs NodeSelector : Taint
- affinity: nodeselector : nodeSelector
3. Deployment HA 구성
Kubernetes의 Deployment를 통해 HA 구성할 때 위의 방법을 사용할 수 있습니다. 가장 간단한 방법은 Deployment를 생성하기 전 서비스를 먼저 생성한 후 Deployment를 생성하면 Kube-scheduler가 자동으로 균등하게 배포합니다. 하지만 특정한 이유로 이를 지정해서 생성해야 할 때 topologySpreadConstraints 와 PodAntiAffinity 를 통해 설정할 수 있습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80PodAntiAffinity의 경우 topologykey를 통해 node의 조건(NodeAffinity에서 Label의 역할)이 되는 기준을 설정할 수 있습니다. 이를 이용해 kubernetes.io/hostname 이 지정된 노드에 app=nginx label의 레이블을 가진 파드가 있을 경우 해당 노드를 피하는 조건으로 각 각 다른 노드에 생성되도록 지정합니다.
단순히 각 노드를 다르게 배포하기 위해서는 위의 방법으로 충분하지만 좀 더 세부적인 조건을 이용하기 위해서는 topologySpreadConstraints를 사용합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80PodAntiAffinity동일한 방법으로 labelSelector를 통해 파드를 지정한 후 topologykey를 통해 노드를 지정합니다. maxSkew는 균등하게 분배되지 않는 정도 나타냅니다. 일반적으로 topologySpreadConstraints 의 경우 대형 클러스터에서 여러 개의 제약조건을 통해 HA 구성을 통해 배포할 때 사용합니다. 각 각의 정책은 AND 조건으로 계산됩니다. 예를 들어 zone으로 구성된 노드 그룹에 비율을 나누고 각 노드에는 하나씩 배포하는 방법. 자세한 문서 참조
4. Deployment HA Service 연결
위의 방법으로 구성한 Deployment를 HA 구성하였는데 이를 사용하기 위한 목적으로는 크게 두 가지가 있다. 첫 번째는 부하분산을 통해 파드에 너무 많은 requests가 가지 않도록 하기 위해, 한 노드가 down 되어도 서비스 중단 없이 사용할 수 있도록 하기 위해 사용한다. 생성한 Deployment를 접근하기 위해서 서비스를 생성해야하는데 다음과 같은 방법을 사용할 수 있다. 이를 테스트하기 위해 생성된 파드에서 nginx의 index페이지에 노드 명을 작성해 접근시 생성된 노드의 이름을 확인할 수 있도록 변경하였다.
4-1. ClusterIP
ClusterIP의 경우 쿠버네티스에서 기본적으로 사용할 수 있는 Service의 종류로 가장 큰 특징은 클러스터 내부에서만 사용 할 수 있습니다. 그렇기 때문에 파드와 파드간 통신에서만 사용할 경우 쉽게 생성할 수 있습니다.(e.g backend 파드와 연결되는 db의 경우 외부접속이 필요 없이 클러스터 내부의 통신만 이용한다)
위와 같이 expose 명령어로 서비스를 생성한 후 endpoint를 조회하면 생성된 파드 3개가 연결된 것을 확인할 수 있습니다. 이후 테스트를 위한 파드를 생성 후 내부에서 Service IP로 접근하였을 때 3개의 파드에 분산하면서 접근합니다.
4-2. LoadBalancer
하지만 ClusterIP는 클러스터 내부에서만 접근이 가능하고 외부에서 접근하기 위해서는 Loadbalancer 또는 Ingress를 사용해야 합니다. LoadBalancer는 Cloud Provider에서 생성한 클러스터는 기본으로 제공하지만 오픈소스로 클러스터를 구성했을 경우 MetalLB로 생성해 사용할 수 있습니다. 현재 클러스터에는 Metal Lb가 설치되어 있지 않아 LB가 제공되는 EKS에서 테스트할 때 동일하게 분산되며 접근하는 것을 확인할 수 있습니다.
4-3. Ingress
ingress는 쿠버네티스 외부에서 유입되는 네트워크를 관리하는 resource로, 외부 접근 가능 URL를 제공, TLS, Domain 기반 접근 등의 기능을 제공합니다. 주로 nginx-ingress를 많이 사용하는데 ingress를 설치하기 위한 서비스 로드 밸런서가 필요하지만 bare-metal에서는 ingress-controller를 NodePort로 배포하여 사용할 수 있습니다. (ingress-controller의 타입을 NodePort로 설치한다)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.3.0/deploy/static/provider/baremetal/deploy.yaml위의 커맨드로 Ingress-controller를 설치한 후 ingress-nginx 네임스페이스에 파드가 실행되는 것을 확인하면 파드에 접근하기 위한 Ingress를 생성합니다. service에서 Deployment가 연결된 ClusterIP의 이름을 지정해 줍니다. host를 지정해 도메인을 통해 접속할 수 있지만 설정하지 않으면 IP를 통해 접속할 수 있습니다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ing
spec:
rules:
#- host: nginx.example.com
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx
port:
number: 80
ingressClassName: nginx이후 ingress-controller의 주소로 노드포트를 통해 접근하면 Loadbalancer와 마찬가지로 파드가 분기되어 접속하는 것을 확인할 수 있습니다.
4-4. NodePort
일반적으로 테스트용으로 많이 쓰는 노드포트의 경우 이러한 상황에서 적합하지는 않지만 구현은 가능합니다. 동일하게 nginx deployment를 노출하는 type으로 nodePort를 선택하고 생성 후 주소로 접근하면 아래와 같이 세 개의 파드에 분기되며 접근하는 것을 확인할 수 있습니다. 다만 배포한 파드의 워커 수만큼 접근할 수 있는 주소가 생깁니다.
위와 같이 파드 3개가 각 각 다른 노드에 배포된 상황에서 한 노드가 다운되어도 내부에서 NAT가 반영되어 나머지 두 노드를 통해 접근합니다. 하지만 실제 서비스에서 다음과 같이 구성할 경우 한 노드가 다운 됐을 경우 IP를 변경해서 접속해야 하기 때문에 적합하지 않습니다.
'Kubernetes' 카테고리의 다른 글
| Thanos를 이용한 Prometheus HA 구성 (1) | 2023.10.12 |
|---|---|
| ArgoCD,Jenkins를 이용한 쿠버네티스 배포 (0) | 2023.10.12 |
| 쿠버네티스 멀티클러스터 관리하기(Feat. Teleport) (1) | 2023.10.12 |
| Kubernetes에서 학습용 Job 생성하기 (0) | 2023.10.12 |
| Kubeflow JupyterNoteBook (0) | 2023.10.12 |